tesseract (JA)
Tesseract OCR
TesseractはRobotのデフォルトの光学式文字認識(OCR)エンジンです。主要なプラットフォームすべてでサポートされている無料のオープンソースコンポーネントです。
統合はTesseractコマンドラインインターフェース(CLI)とローカルファイルシステムに基づいています。デスクトップ画像は精度向上のため拡大(スケールアップ)され、8ビット白黒形式でシステム一時パス内のファイルに保存されます。その後、この手法は画像ファイルを引数としてCLI経由でTesseractを起動します。エンジンはOCR処理を実行し、認識されたテキストを一時パス内のテキストファイルに保存します。このファイルはその後Robotによって解析されます。
セットアップ手順
最初のステップとして、お使いのシステムでTesseractが利用可能かどうかを確認してください:
ロボットを起動し、メインメニューでOCR → 推奨OCRエンジンを選択を選択してください
エンジンドロップダウンでTesseractが選択されていることを確認してください。
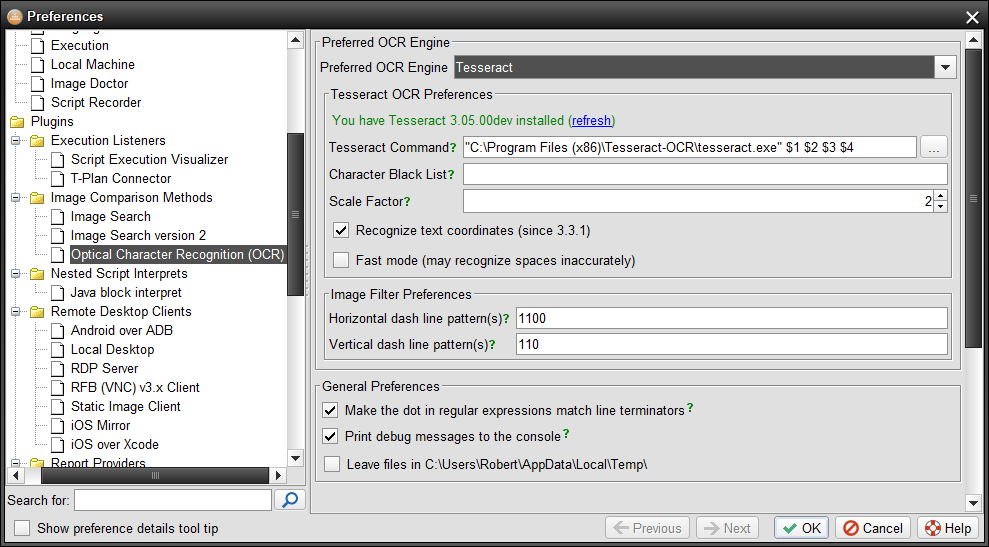
「Tesseract XXX がインストールされています」 のような緑色のメモが表示されている場合は、準備完了です。そうでない場合は、以下の手順に従ってインストールしてください。
Tesseractのインストール
Linuxをお使いの場合は、パッケージマネージャーを使用して「tesseract」パッケージをインストールしてください。ください。
その他の場合は、Tesseractをダウンロードしてインストールしてください(手順).
Windowsでは、オプションの言語ファイルもインストールする最新のUB Mannheim Tesseractインストーラーオプションのの使用を強く推奨します。
Tesseract バージョン5では、認識テキスト内のフォームフィード文字を抑制するために、Robotリリース6.3以降が必要です。
デフォルトでは、tesseractバイナリがシステムパス上に存在すると想定しています。存在しない場合は、上記画像のTesseractコマンドフィールドを適切に更新してください。例えば、エンジンを C:\Program Files\Tesseract フォルダにインストールした場合、コマンドテンプレートを以下のように更新します:
"C:♪Program Files (x86)♪Tesseract-OCRtesseract.exe" $1 $2 $3 $4
テッセラクトの検証
統合統合をテストするには、スクリプトエディタを開いた状態でスクリプト → 比較コマンドウィンドウを開きます。比較方法ドロップダウンから「tocr」を選択し、ウィンドウがTesseractを確認するのを待ちます。
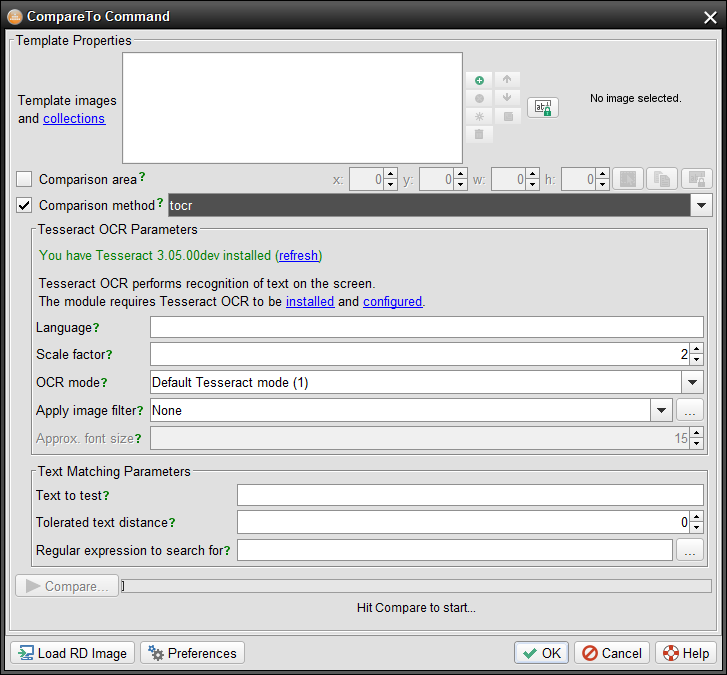
Tesseract OCRが正しくインストールおよび設定されているかどうかをテストするには、テスト環境への接続状態を維持したまま、"Compare"ボタンから「tocr」認識を実行してください。これによりOCR結果が表示されるか、エンジンから発生したエラーが表示されます。最も一般的なエラーは以下の通りです:
テッセラクトはまったくインストールされていません。
Tesseractはインストールされていますが、システムパスに追加されていません。この場合、環境設定ウィンドウ内のTesseract OCR設定パネルを探し、コマンドテンプレートを「tesseract」バイナリへの完全なパスで更新する必要があります。
Tesseractはインストールおよび設定済みですが、言語データファイルが存在しないか、言語パラメータで指定されたファイルがありません。この場合、言語ファイルをダウンロードし、Tesseractが要求するフォルダに保存する必要があるかもしれません。
Tesseractの認識能力は最も一般的なフォントと言語に限定されるため、T-Planは特定のテスト環境における正確性および互換性を保証しません。Tesseractエンジンは特定のフォントや言語設定向けに最終的に「トレーニング」することが可能です。手順はTesseractのドキュメントに記載されています。
精度はロボット側では以下の2つのパラメータを通じてのみ制御可能です:
cmpareaパラメータを用いて認識範囲を特定の画面領域に限定することで、精度が大幅に向上します。デスクトップ全体の認識はエンジンを混乱させるようで、実際には存在しない場所にテキストを検出することが頻繁に発生します。これにより多くのエラーを含む予期せぬ結果が生じます。
エンジンが1~2文字の単独文字列を認識できない問題があるため、長いテキスト(3文字以上)でのみ使用してください。
「範囲」パラメータの値を2.5や3など大きくすると、例えばフォントが非常に小さい場合などに、精度がわずかに向上する可能性があります。
自動化
OCRを利用するすべてのコマンド(例:CompareTo, WaitFor, ClickそしてDragテッセラクトは、は優先エンジンを使用し、自動的にTesseractを検出します。
OCRが設定ミスやI/Oエラーによるエラーをスローした場合、呼び出しコマンドは1を返します。エラーのテキストは_TOCR_ERROR変数を通じて利用可能です。この変数の存在をテストすることは、スクリプト内でコアOCRエラーを検出する方法です。
テッセラクトOCR固有のパラメータは5つあります:
language=<3文字言語コード>
言語パラメータは、適切にインストールされたTesseract言語データファイルの有効な3文字言語コードである必要があります。パラメータが省略された場合、デフォルトで「eng」(英語)が使用されます。
scale=<scaleFactor>
スケールパラメータは、デスクトップ画像がTesseractに渡される前に拡大される倍率を定義します。拡大縮小は精度に影響を与える可能性があります。詳細はトラブルシューティングの項を参照してください。
スケール値は1.5、2、3などの任意の浮動小数点数に設定可能です。高いスケール値はメモリ要件を大幅に増加させ、Robotのメモリ不足(OutOfMemoryError)を引き起こす可能性があります。デフォルトのスケール係数は2です。
mode=<modeNumber>
オプション認識モード(バージョン3.5以降でサポート)。エンジンの動作を変更し、より良い結果を得ることを可能にします。サポートされているモードは以下の通りです:
デフォルトのテッセラクトモード (コード "1")。これはテッセラクトのデフォルトモードであり、OSDなしの自動ページ分割(「-psm 3」CLIスイッチ)を行います。この値は3.5以前のRobotリリースと互換性があります。
高精度 (コード "2")。これは画面上のテキストを行単位に分割し、行モード (-psm 7) で個別にOCRを再適用するロボットの強化機能です。この手法は処理速度が数倍遅くなりますが、特にアプリケーションウィンドウのような小さな画面領域にOCRを適用する場合、通常より正確な結果をもたらします。
画像を単一の単語として扱う (コード「8」)。認識されるテキストが最大3文字の場合にこのモードを使用します。これは「-psm 8」CLIスイッチで駆動されるTesseractのネイティブモードです。
Robotバージョン4.0.1以降では、追加モードがサポートされています:
可変サイズの単一テキスト列を想定(コード「4」)。これはTesseract CLIスイッチ「-psm 4」に対応する。
垂直方向に整列された単一の均一なテキストブロック(コード「5」)を想定する(Tesseract CLIスイッチ「-psm 5」に対応)。
単一の均一なテキストブロック(コード「6」)を想定する(Tesseract CLIスイッチ「-psm 6」に対応)。
画像を単一のテキスト行として扱う(コード「7」)は、Tesseract CLIスイッチ「-psm 7」に対応します。
画像を円内の単一単語として扱う(コード「9」)は、Tesseract CLIスイッチ「-psm 9」に対応します。
画像を単一の文字として扱う(コード「10」)これはTesseract CLIスイッチ「-psm 10」に対応します。
filter=<filterNumber>
オプションの画像フィルター(バージョン3.5以降)。OCR精度向上のため、画面上の特定のアーティファクトを除去します。このフィルターは、対象画面またはその一部に、例えば標準的な単色グレーや白のボタン、ドロップダウンメニューなどのコンポーネントを含むアプリケーションウィンドウのように、長方形の単色領域内に濃い色のテキストが含まれる場合に選択的に適用する必要があります。白色や明るい色のテキスト、画像や写真などの豊かな色彩のグラフィックには適していません。このような場面でフィルターを使用すると、テキストが損なわれOCR精度が低下する可能性があります。
fontsize=<フォントサイズ>
認識されたテキストのおおよそのフォントサイズ(バージョン3.5以降)。デフォルト値は15です。画像フィルターが有効な場合のみ使用されます。この値は、フォントサイズ以下の人工物(アーティファクト)を除去しないようフィルターに指示します。実際のフォントサイズより大幅に小さい値を設定すると、フィルターが文字の一部を損なう可能性があります。値が大きすぎると、フィルターが画面上の特定のアーティファクト(構成要素)を除去できず、認識精度が低下する可能性があります。