Image Based Text Recognition
1.概要
画像ベース文字認識(IBTR)は、T-Plan Robot Enterprise 3.0で導入された新機能であり、事前に保存された文字の集合に基づいて画面上の文字とその座標を認識します。IBTR機能は以下の3つのコンポーネントで構成されています:
-
スクリプト言語仕様に記載されている「テキスト」比較方法。
-
キャラクター画像コレクション
-
キャラクターキャプチャウィザード
この機能は、2.x リリース用のアドオンとして提供されている画像ベーステキスト認識プラグインとパラメータ互換性がありません。プラグインベースのスクリプトコードを変換するには、許容値パラメータを合格率パラメータに置き換えてください。
合格率 = 100 * (1 - 許容値/85)
サンプル許容値を合格率に変換したおおよその対応表:
|
許容度(tolerance) |
合格率(passrate) |
|---|---|
|
0 |
100 |
|
10 |
88 |
|
20 |
76 |
|
30 |
65 |
|
40 |
53 |
|
50 |
41 |
|
60 |
29 |
|
70 |
18 |
|
85 |
0 |
2. キャラクター画像コレクション
キャラクター画像コレクションとは、以下の規約を満たすキャラクター画像を含むディレクトリを指します:
-
コレクションディレクトリには、「uNNNN」という名前のフォルダ(「文字フォルダ」)のみが含まれます。ここで「NNNN」は4桁の大文字の16進数UTF-8文字コードです。例えば、「M」文字はUTF-8コードが77(0x4D)であるため、「u004D」という名前のフォルダで表される必要があります。
-
各キャラクターフォルダには、Javaがサポートするロスレス形式(PNGが推奨、BMPもサポートされるがファイルサイズが大きくなる傾向がある)のキャラクター画像が1つ以上含まれます。画像ファイル名は重要ではありませんが、ファイル拡張子は画像形式に応じて正しく設定する必要があります。例えば、PNG画像は「.png」拡張子のファイルに保存しなければなりません。
'a'文字の2つのバリアントと'o'文字1つを含む文字コレクションの例は次のようになります:C:\MyAutomation\charset
-
u0061\
-
a1.png
-
a2.png
-
-
u006F\
-
o.png
-
コレクションのおすすめ
-
内部アルゴリズムがコレクション画像からテキスト行の高さとスペースサイズを導出するため、異なるフォントタイプおよび/またはサイズの文字画像を単一のコレクションに混在させてはいけません。異なるフォントや背景色の文字画像を混在させることは、文字が同じフォントタイプおよびサイズである限り問題ありません。
Robotはキャラクターキャプチャウィザードによるキャラクター画像コレクションの作成と管理をサポートしていますが、規約を満たす限り、そのようなコレクションは手作業またはサードパーティ製画像エディタで作成・編集することも可能です。これは、IBTR内部で使用される画像検索アルゴリズムの特定の機能を活用するのに有用です。例えば、あらゆる背景で機能するキャラクターコレクションを作成するには、画像編集ソフトでキャラクター画像を編集し、背景を透明または半透明にすることができます。
3.2 文字キャプチャウィザード
文字キャプチャウィザードは、文字画像コレクションの作成、表示、管理を可能にするフロントエンドGUIウィンドウです。このウィザードは、OCR->文字キャプチャメニュー項目から起動できます。
最初のウィザード画面「画像コレクションの選択」では、使用するキャラクター画像ディレクトリの選択を行います:
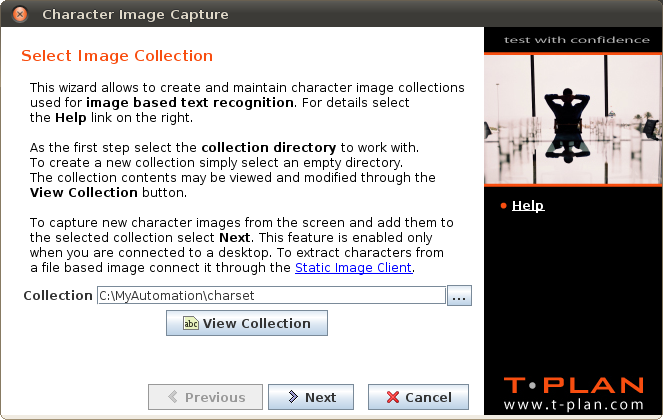
コレクションを表示ボタンは、コレクションフィールドに既存のディレクトリが指定されている場合にのみ有効になります。このボタンをクリックすると、新しいウィンドウが開き、コレクションの詳細が表示されます。詳細には、文字画像のツリー構造と、コレクションでカバーされている文字を示すUTF-8文字セット表が含まれます。ビューアでは、文字画像の編集や削除などの基本的なメンテナンス作業も実行できます。
選択したコレクションに新しい文字画像を追加するには、次へをクリックしてテキスト選択画面に進みます。このボタンは、Robotがデスクトップに接続されている場合にのみ有効になります。ファイルに保存された静止画像から文字を抽出する必要がある場合は、ログインウィンドウを使用して静止画像クライアント経由で画像をロードしてください。
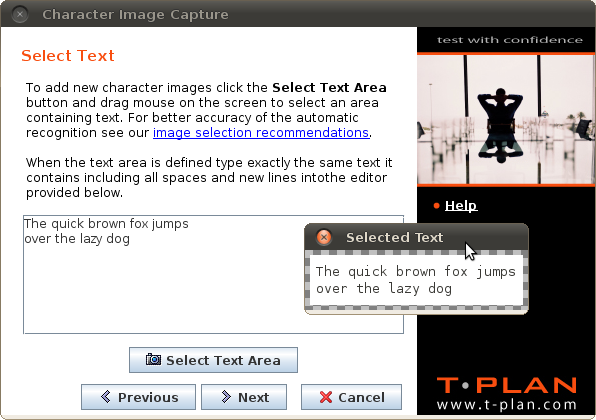
To extract new characters from the screen perform the following steps:
-
テキスト領域を選択ボタンをクリックしてください。リモートデスクトップのコピーが表示された新しいウィンドウが開きます。次に、画像上でマウスをドラッグしてテキストを含む領域をマークします。テキスト選択のコツについては、下記の推奨事項の章を参照してください。選択に問題がなければ、選択範囲の横にある緑色のチェックマークボタン、またはツールバーの保存して閉じるボタンのいずれかをクリックしてください。
-
画像に含まれるテキストを、ボタン上部のエディターに入力してください。表示されている通り、スペースや改行を含め正確に入力してください。
画像を選択しテキストを入力したら、キャラクター画像の確認という最終画面に進むため「次へ」をクリックしてください:
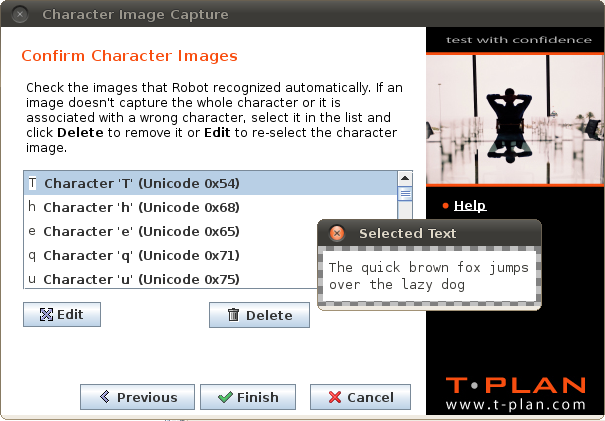
この画面には、入力されたテキストに含まれる文字の一覧が表示されます。ロボットが画像内の個々の文字をピクセルレベルで認識した場合、提案された文字画像が一覧に追加されます。削除および編集ボタンで文字を削除または変更できます。重複する画像を処理する必要はありませんのでご注意ください。既存の文字画像が新規抽出画像と同一の場合、自動的にスキップされます。テキスト領域画像から個々の文字を解析できない場合があります。例えば、選択されたテキスト領域が推奨基準を満たさない場合などが該当します。未認識の文字はリスト上で赤いN/Aアイコン(例:)と共に表示されます。

この動作は、文字コレクションを使用してその文字を検索できないことを意味するものではありません。単にウィザードが文字イメージを提案できなかったことを示しています。修正するには、リストから該当文字を選択し、編集をクリックして、テキストエリアに手動でそのイメージを定義してください。
テキストエリア選択に関する推奨事項
以下のヒントは、画面上のテキスト領域を選択する方法を示し、手動で修正が必要な未認識文字(N/A)の数を最小限に抑えるためのものです:
-
選択領域の最初のピクセル(左上隅)は背景色でなければなりません。
-
領域には単一のフォント種別、サイズ、色のテキストが単色背景上に表示されている必要があります。例えば、白地に黒文字のブロックなどが該当します。テキストがこれらの要件を満たさない場合、この基準を満たす小さな部分(単語単位および/または行単位)に分割して処理してください。
-
領域には、単一のグラフィックコンポーネント上に表示される連続したテキストブロック(テキストメッセージ、ボタンラベル、メニュー項目など)を含める必要があります。例えば、水平軸に沿ってテキストの位置が異なる可能性があるため、2つ以上のボタンを含む領域を選択しないでください。
-
ロボットは背景色のスペースを基準に文字を分離するため、縦軸または横軸に沿って文字が重なっているフォントは解析に失敗し、手動で抽出する必要があります。そのような文字画像に別の文字の一部が含まれている場合、Gimpなどのサードパーティ製画像編集ソフトでそれらを除去し、影響を受けた部分を透明化して文字検索アルゴリズムがそれらをスキップできるようにしなければなりません。
3.3 「テキスト」比較法
テストスクリプトレベルでは、画像ベースの文字認識が「 text」という新しい比較メソッドとしてサポートされており、CompareTo、Screenshot、Waitfor match/mismatchコマンド、またはそのJavaテストスクリプト対応メソッドの呼び出しを通じて使用できます。この比較メソッドは以下のパラメータをサポートします:
-
標準の比較パラメータ「cmparea」および「passrate」がサポートされています。「cmparea」は、画面上の特定の矩形領域に文字認識を制限するために使用できます。「passrate」は現在使用されていません。呼び出しコマンドで定義されていても無視されます。
-
"chars"パラメータは必須であり、文字画像コレクションのパスを定義します。パスが相対パスである場合、スクリプトのテンプレートディレクトリを基準に解決されます。
-
"tolerance" パラメータは、エンタープライズ画像検索メソッド(「search」) でサポートされているものと同様です。0 から 256 までの整数でなければなりません。これは、デスクトップピクセルの赤、緑、青の各成分が、対応する文字画像ピクセルと同等と見なされるために許容される最大差異を示します。この値により、わずかな差異で描画される文字を動的に検索することが可能になります。このパラメータが指定されていない場合、デフォルトは 0 となり、アルゴリズムは正確な色の一致を用いてピクセルを比較します。
-
"テキスト", distance」および「pattern」パラメータは、Tesseract OCR メソッド(「tocr」) の対応するパラメータと同じ機能を果たします。
このメソッドはTesseract OCRメソッドと同じ戻り値を返します。 "text"、"distance"、 " テキスト認識パラメータが使用されない場合、呼び出しコマンドは実際にテキストが認識されなくても、実行が成功したことを示すために 0 (成功) を返します。テキスト一致パラメータが使用された場合、呼び出しコマンドは認識されたテキストが一致するか否かに応じて成功(0)または失敗(0以外の値)を返します。このメソッドはTesseract OCRメソッドと同様の変数セットも設定します。これらは呼び出しスクリプトが認識されたテキストを処理するために使用できます:
|
変数名 |
説明 |
|---|---|
|
_TEXT=<text> |
認識されたテキスト(完全な複数行形式)。この変数は、メソッドが正常に実行された場合(デスクトップ接続の欠如や無効な文字画像コレクションによる失敗がない場合)に常に作成されます。 |
|
_TEXT_LINE<n>=<text> |
解析されたテキスト行で、<n> は行番号です。番号付けは1から始まります。メソッドが単一のテキスト行のみを認識した場合、_TEXT変数の内容は _TEXT_LINE1 と等しくなります。 |
|
_TEXT_LINE_COUNT=<number> |
認識されたテキストの行数。 |
|
_TEXT_ERR=<error_text> |
エラーメッセージ。テキスト認識が失敗した場合にのみ表示されます。例えば、デスクトップ接続がない場合、または指定された文字画像コレクションが存在しない、もしくは読み取れない場合などが該当します。 |
|
_TEXT_MATCH=<text> |
「text」および「distance」パラメータで指定された条件を満たすファジーマッチングを生成した認識済みテキストの部分。 |
|
_TEXT_MATCH_INDEX=<number> |
_TEXT_MATCH_で記述された一致テキストの位置(インデックス)。インデックスは認識されたテキストの先頭に対応する0から開始します。 |
以下の例は、.tprスクリプト内でテキスト認識を呼び出す方法を示しています。テキストマッチングに関するより高度な例は、このメソッドの動作を主に模倣している Tesseract OCR メソッドのドキュメントで確認できます。
Compareto method="text" chars="C:\MyAutomation\charset"
Screenshot test.jpg method="text" chars="C:\MyAutomation\charset"
Waitfor match method="text" chars="C:\MyAutomation\charset"